Abstract: These exercises will familiarize with more advanced machine learning concepts including hyperparameter tuning and cross-validation. You will also see how to visualize the model that is learned by a machine learning classifier.
Strategies for Preventing Overfitting: Regularization
Last time we discussed machine learning we examined the tradeoff of the number of training examples and the performance of the model on predicting new instances. We did this by producing graphs of model performance as a function of the amount of training data used:
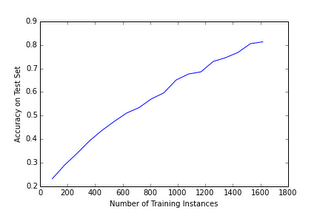
This graph shows the performance of a logistic regression model at predicting which of digit is represented by an 8 pixel by 8 pixel grayscale image of a hand written digit.
While it is nice that the model’s performance increases as we add more data, it would be nice if there was a way to have it all: better performance with less data. Fortunately, many machine learning algorithms have strategies that attempt to achieve this goal. Consider the objective function of the standard logistic regression model that we talked about a couple of lectures ago:
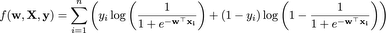
We can augment this objective with a term that serves to penalize large weights (i.e. large values of the entries of w). This modification serves to reduce the flexibility of fitting the training data, thereby improving the performance on predicting future data. The modified objective function is:
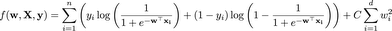
Where C is a positive constant that balance how much we care about fitting the training data compared to penalizing large weights. To understand this a bit better, let’s consider the limiting behavior. How would this new version of logistic regression behave as C goes to 0? How about as C goes to infinity?
We can rerun our experiment on learning to recognize handwritten digits with this modified version of logistic regression. For starters, let’s just use the default value of C=1. The learning curve now looks like this:
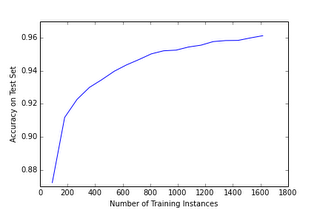
Woah! This is a lot better… However, we might ask ourselves whether we can do even better if we tuned the value of C a little bit.
Tuning Hyper Parameters
It turns out that properly tuning the values of constants such as C (the penalty for large weights in the logistic regression model) is perhaps the most important skill for successfully applying machine learning to a problem. Let’s see how this learning curve will look with different values of C:
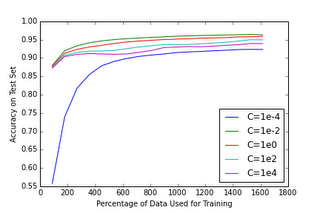
If we zoom in a bit on the more interesting part of the graph:
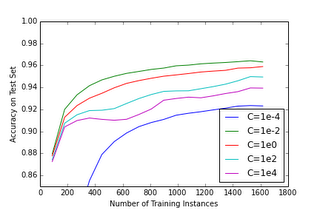
It looks like we can do a bit better than the default value of C=1 by choosing C=0.01. How well do would we expect our model to do on predicting images of handwritten digits if we were to collect a brand new database?
Luckily, Scikit-learn provides some built-in mechanisms for doing parameter tuning in a sensible manner. One such method is to use a cross validation to choose the optimal setting of a particular parameter.
Cross validation can be performed in scikit-learn using the following code:
